赛优市场店员积累了丰富的神秘顾客经验,严谨,务实,公平,客观.真实的数据支持!


发布日期:2024-01-02 20:24 点击次数:105
著作开始:新智元重庆房地产第三方神秘客暗访
 图片开始:由无界 AI生成
图片开始:由无界 AI生成
昨天,一篇系统性地研究了GPT-4为什么会‘降智’的论文,激励了AI圈的世俗照料。
跟着各人对GPT-4使用得越来越相同,用户每过一段时刻都会皆集反馈,GPT-4好像又变笨了。

最近的情况是,要是用户不提神和GPT-4说当今是12月份,GPT-4的输出的本色就会彰着变少。
有一位用户挑升作念了一个测试,分歧告诉GPT-4当今是5月份和12月份,然后对比输出效能,发现12月份的效能比5月份差了不少。
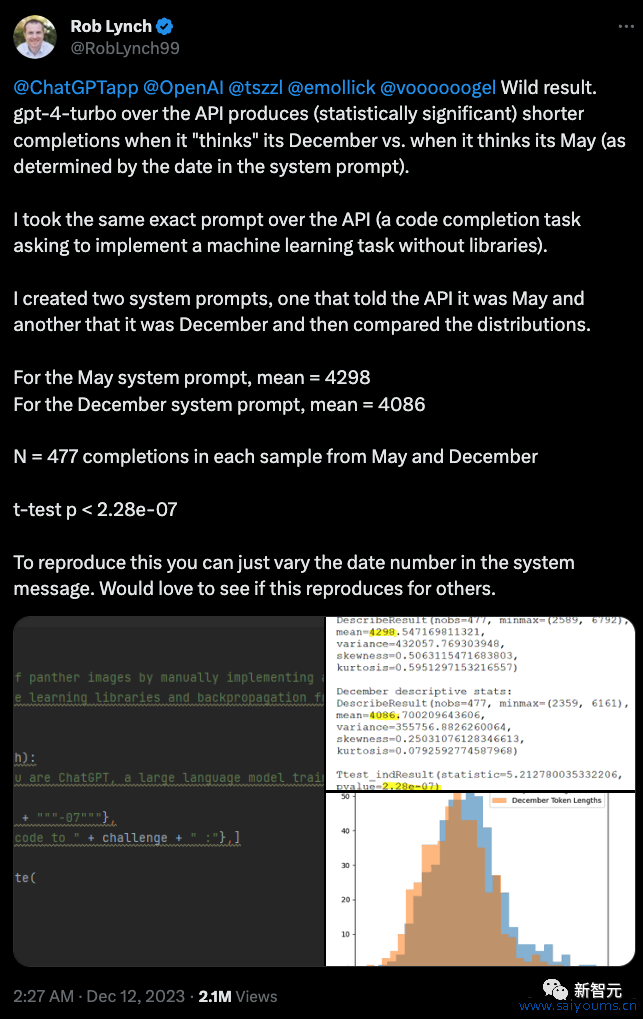
各人照料都合计是说GPT-4会给我方放寒假,看到12月份就不思干活了。
然则要是放在这篇论文中来看,作家认为,最主要的原因是大模子有一个当今看来险些是无解的弱势——衰退合手续学习和进化才能。

论文地址:https://arxiv.org/abs/2312.16337
咱们发当今LLM在磨练数据创建日历之前的数据集上的进展,要彰着好于在磨练日历之后发布的数据集的进展。
岂论是零样本照旧千般本的测试中,LLM都会呈现出这种情况。
论文还指出,LLM在他们以前真确‘见过’的任务上进展高超,而在新任务上进展欠安,压根原因照旧因为仅仅记着了谜底,而莫得目的有用地获取新常识和泄漏。
而变成这种进展隔离如斯纷乱的原因,就在于‘任务稠浊’。

在上表中,作家发现不错从GPT-3模子中都能索取任务示例,而且从davinci到GPT-3.5-turbo的每个新版块中,索取的磨练示例数目都在加多,与GPT-3系列模子在这些任务上的零样人道能提升密切商量。
说白了,之是以模子在结果时刻之前的数据集测试进展高超,是因为磨练数据中也曾包含了数据皆集的问题。
这充分评释了GPT-3系列各个版块在这些任务上的性能增强是由任务稠浊导致的。
关于那些不存在职务稠浊字据的分类任务,大型话语模子很少能在零样本和少样本建立下显赫优于简便广博基准。
在上表中,研究东说念主员也列出关于51个后磨练数据网罗且无索取任务示例的模子/数据集组合中,独一1个组合的模子能在零样本或少样本建立下显赫优于广博基准。
这评释一朝莫得任务稠浊的可能性,LLM的零样本和少样本进展其实并不稀奇。
网友们看了之后悲不雅地暗示:现时很难构建梗概合手续合乎且不会对已编码的往常常识和新常识变成苦难性插手的机器学习模子。

ChatGPT是往常互联网的快照 - 跟着互联网的变化,ChatGPT 在有用任务的常识和性能方面都变得过期了。
OpenAI和大模子公司都必须濒临这么一个事实——他们必须不休从头磨练新模子。
也许,这就某种经过上为什么没过一段时刻,东说念主们就会发现ChatGPT又变笨了,也许仅仅因为你不休地在用新问题考它,它的确切水品镇静地被暴泄漏来了。
测试模子
研究东说念主员针对12个模子进行了测试:
5个OpenAI发布的GPT模子,7个开源的LLM。
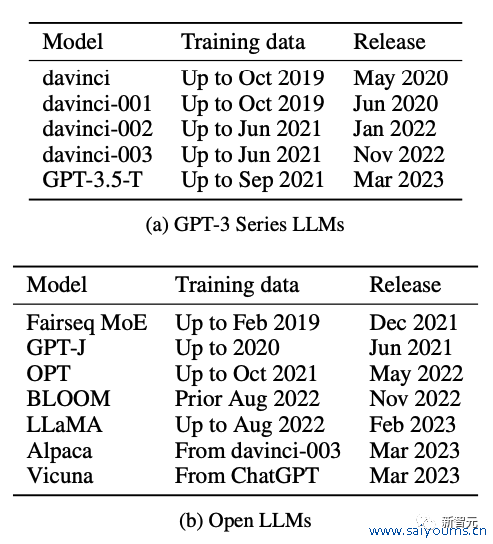
针对这些模子,他们登第了两组刚好卡在模子磨练时刻前后的数据集进行了测试。
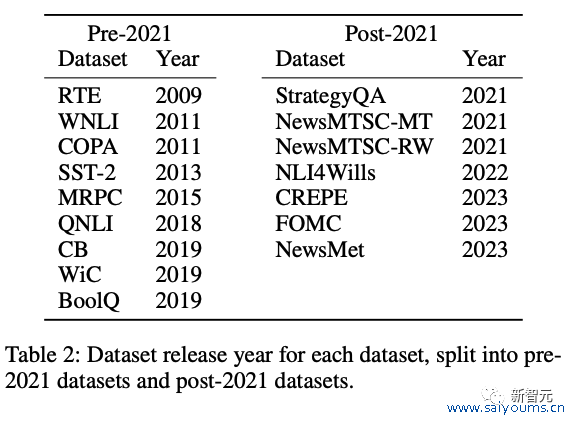
测试步调
时序分析
然后研究东说念主员分歧测试了不同模子在洽商两组数据集上的进展。从效能不错彰着看出,在模子数据磨练结果日历之后发布的数据集,零样本和千般人道能彰着要差了好多。

关于12个模子和16个数据集,研究东说念主员进行了192个模子/数据集组合。
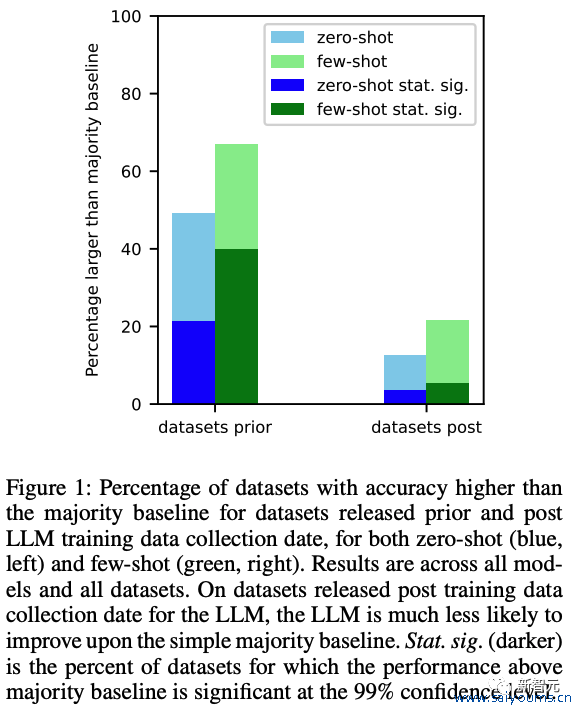
在这些组合中,136 个数据集在 LLM 培训数据网罗日历之前发布(网罗前),神秘顾客介绍56 个数据集在之后发布(网罗后)。关于这两个荟萃,咱们狡计模子打败大广博基线(零样本和少样本)的模子/数据集组合的百分比。
效能如下图 1 所示。咱们发现,关于在创建 LLM 之前发布的数据集,LLM 更有可能在零和少数样本建立上打败广博基线。
前区一号球分析:上期开出奖号07,该位最近10期出现范围在03-13之间,中点为08,其中中点两端分别出现5次,中点08没有出现,本期看好该位走大,注意中位号码以上号码,关注号码13。
前区奇偶、大小分析:最近10期奇偶比为29:21,奇数奖号明显占优,上期奇偶比为2:3,本期注意奇数号码占优,奇偶比看好4:1;上期大小比为3:2,连续10期奖号大小个数比为34:16,大号优势出现,本期预计大号保持优势,大小比看好4:1。
针对单个的LLM,进一步发现:
针对每个LLM单独进行测试。效能如上图2所示。这么的趋势在具有全领域日历的模子中保合手不变,进一步标明数据集的皆备日历不是主要身分,而是日历数据集相干于法学硕士磨练数据网罗日历的变化是更紧迫的身分。
任务示例索取分析
要是LLM梗概生成与测试数据中的示例完全匹配的示例,则解释LLM在磨练技术也曾看到了该任务的测试集。
研究东说念主员经受访佛的步调来测试任务稠浊。他们不尝试生成测试数据,而是领导模子生成磨练示例,因为关于零次或少次评估,模子不应在职何任务示例上进行磨练。
要是LLM不错根据领导生成磨练示例,这等于任务稠浊的字据。
下表4炫夸了扫数模子中扫数任务的任务示例索取效能。

进一步研究东说念主员还发现,关于莫得被解释存在职务稠浊可能性的任务,LLM很少进展出比大广博基线具有统计明显性的翻新。
在上表4中,关于网罗后且莫得索取任务示例的 51 个模子/数据集组合,51 个模子/数据集组合中独一 1 个(即 2%)在零样本或少样本建立的情况下进展出相干于大广博基线的统计明显翻新。
成员推理分析
为了进一步检查磨练数据稠浊的影响,研究东说念主员欺诈了成员推理膺惩来检查模子生成的本色是否与数据皆集的示例完全匹配。
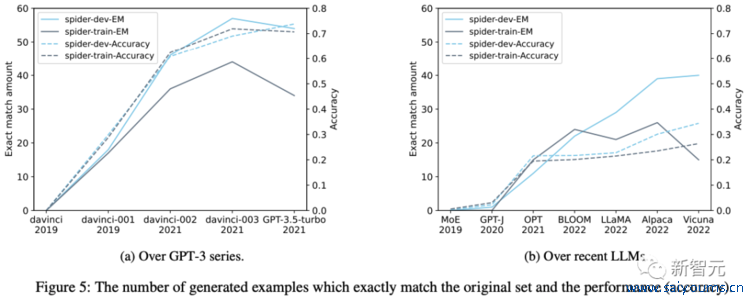 上图5a和图5b分歧炫夸了GPT-3系列版块和最新开源 LLM 的采样磨练集和完好开导集生成的示例有若干是完全洽商的。
上图5a和图5b分歧炫夸了GPT-3系列版块和最新开源 LLM 的采样磨练集和完好开导集生成的示例有若干是完全洽商的。
因为数据库花式(atabase schemas )不在零样本领导中,因此要是模子不错生成与磨练或开导数据中完全洽商的表名或字段名,则一定存在稠浊。
如图5所示,精确匹配生成的示例数目跟着时刻的推移而加多,这标明Spider上的任务稠浊经过正在加多。
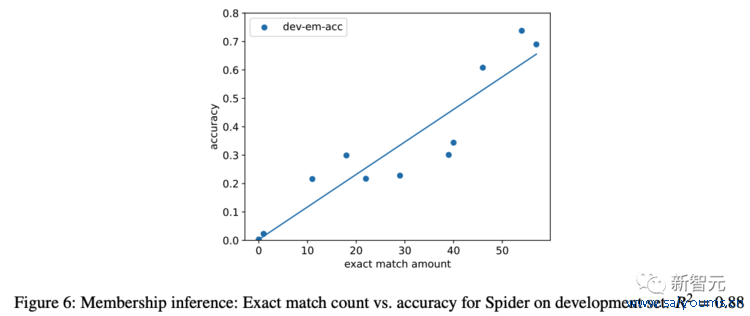
他们还在领导中添加花式后狡计推行准确性,并将其与完全匹配的代数进行画图(图 6)。咱们发现完全匹配的生成示例数目与推行准确性之间存在很强的正商量性(? = 0.88),这热烈标明稠浊的加多与性能的提升商量。
参考贵府:
https://arxiv.org/abs/2312.16337
股市回暖,抄底炒股先开户!智能定投、条目单、个股雷达……送给你>>
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负裁剪:欧阳名军 重庆房地产第三方神秘客暗访

Powered by 重庆房地产第三方神秘客暗访 @2013-2022 RSS地图 HTML地图
Copyright 站群 © 2013-2022 粤ICP备09006501号
